人民网领导留言板文本数据,在科研中应用颇丰,本次我们分享该数据并利用留言板文本数据样本进行主题建模。数据及代码获取方式见后文。
一、领导留言板数据
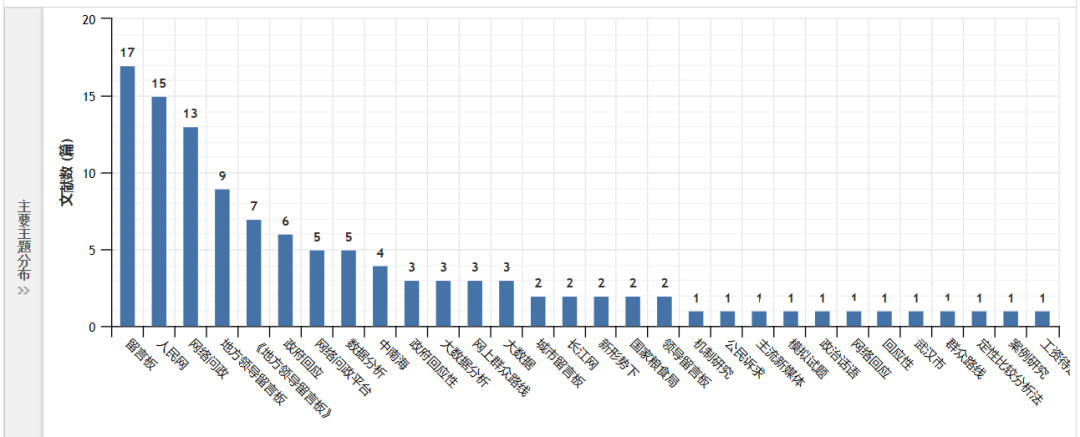
从人民网获取领导留言板数据,时间跨度为2019年12月-2022年5月,记录留言版代码留言版代码,共20字段,其数据字段如下:
#字段
领导ID
地方领导
所属省份
用户
用户地区
留言内容
留言时间
留言类别ID
留言类别
留言主题
留言类型
点赞数
处理状态
回复机构
回复内容
回复时间
满意程度评分
解决程度评分
办理态度评分
办理速度评分
二、LDA主题建模部分代码
import pandas as pd
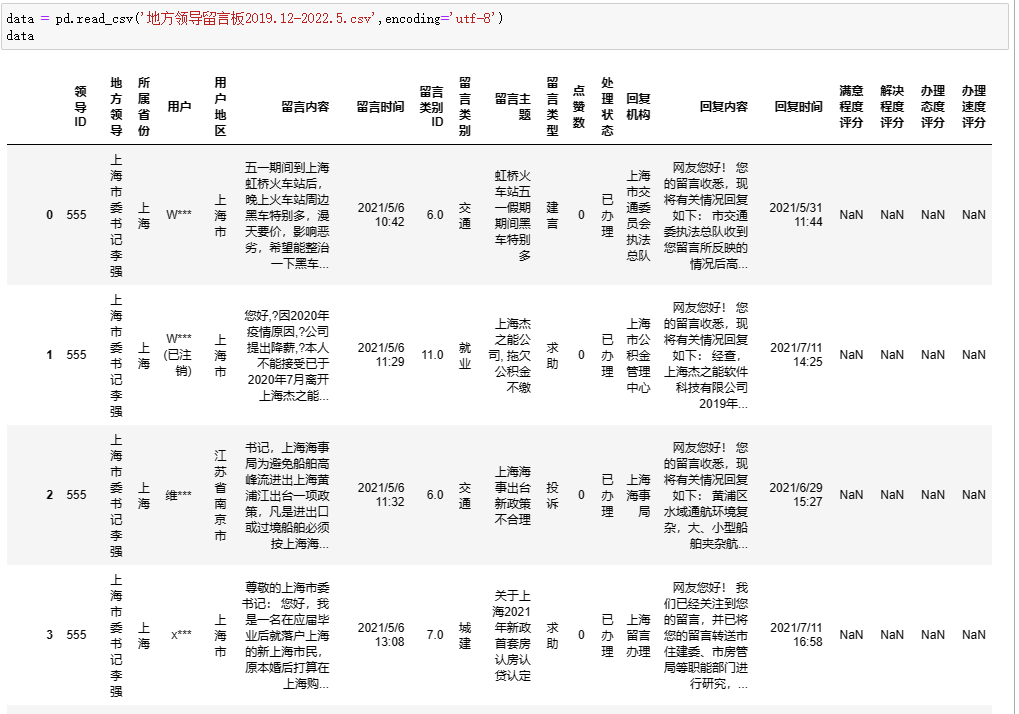
data = pd.read_excel('Case/留言数据.xlsx')
data.head()
import re
import jieba
stopwords = open('data/dict/stoplist.txt',encoding = 'utf-8').read().split('n')
def clean_text(text):
text = re.sub(r'd+','',text)
words = jieba.lcut(text)
words = [w for w in words if w not in stopwords]
return ' '.join(words)
data['content'] = data['text'].apply(clean_text)
data.head()
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
vectorizer = CountVectorizer(max_df = 0.5,min_df=10,max_features = 1000)
doc_term_matrix = vectorizer.fit_transform(data['content'])
doc_term_matrix
# 构建LDA话题模型
from sklearn.decomposition import LatentDirichletAllocation
lda_model = LatentDirichletAllocation(n_components = 4,#话题数
max_iter = 50,
learning_method = 'batch',
learning_offset = 50,
random_state = 20230212)
lda_output = lda_model.fit_transform(doc_term_matrix)
print(lda_model) #模型参数
print(lda_output) #话题分布情况
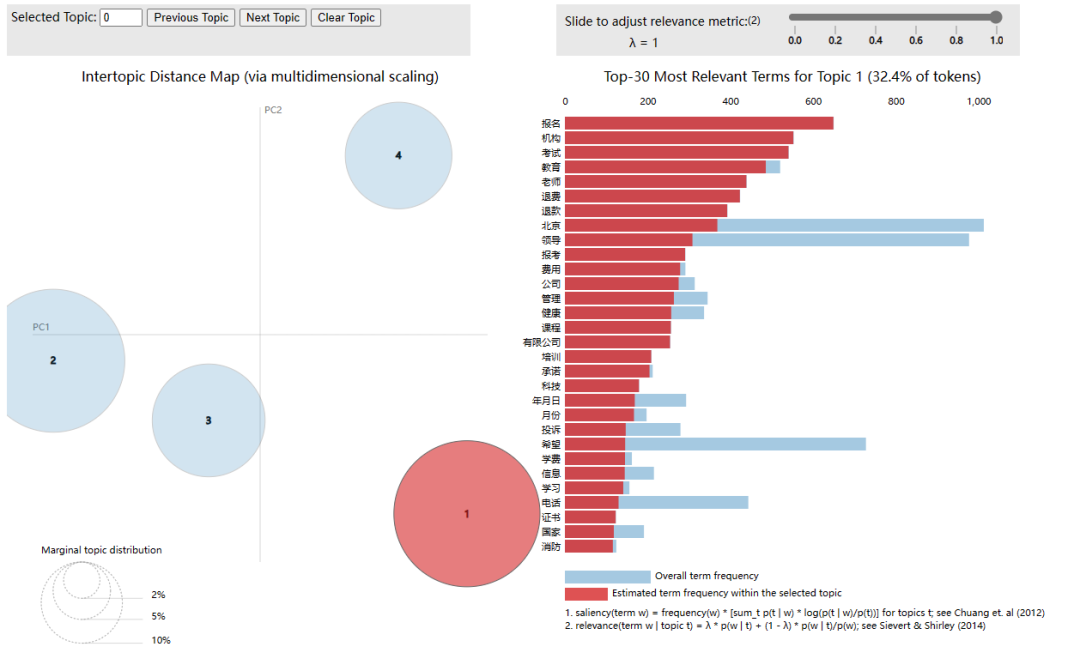
import pyLDAvis
import pyLDAvis.sklearn
import warnings
warnings.filterwarnings('ignore')
pic = pyLDAvis.sklearn.prepare(lda_model,doc_term_matrix,vectorizer)
pyLDAvis.display(pic)
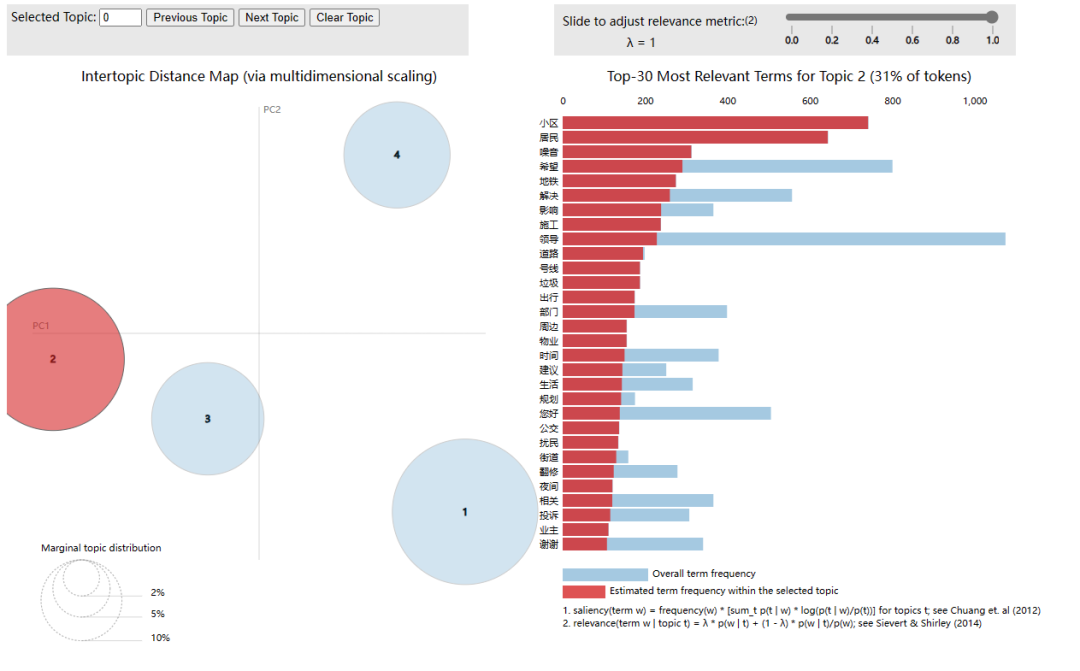
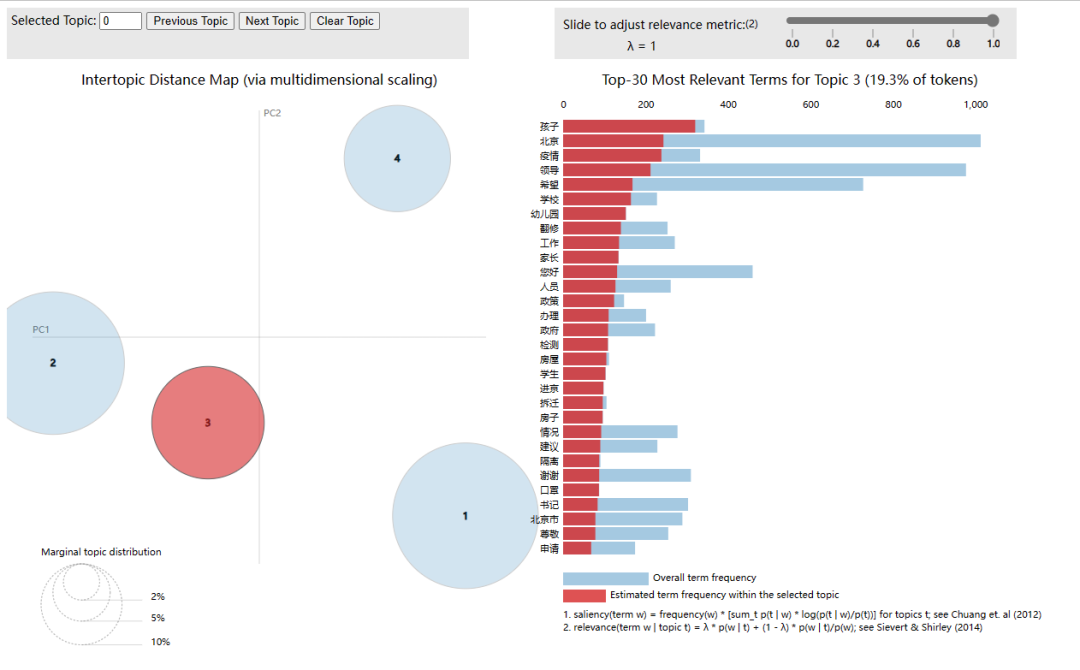
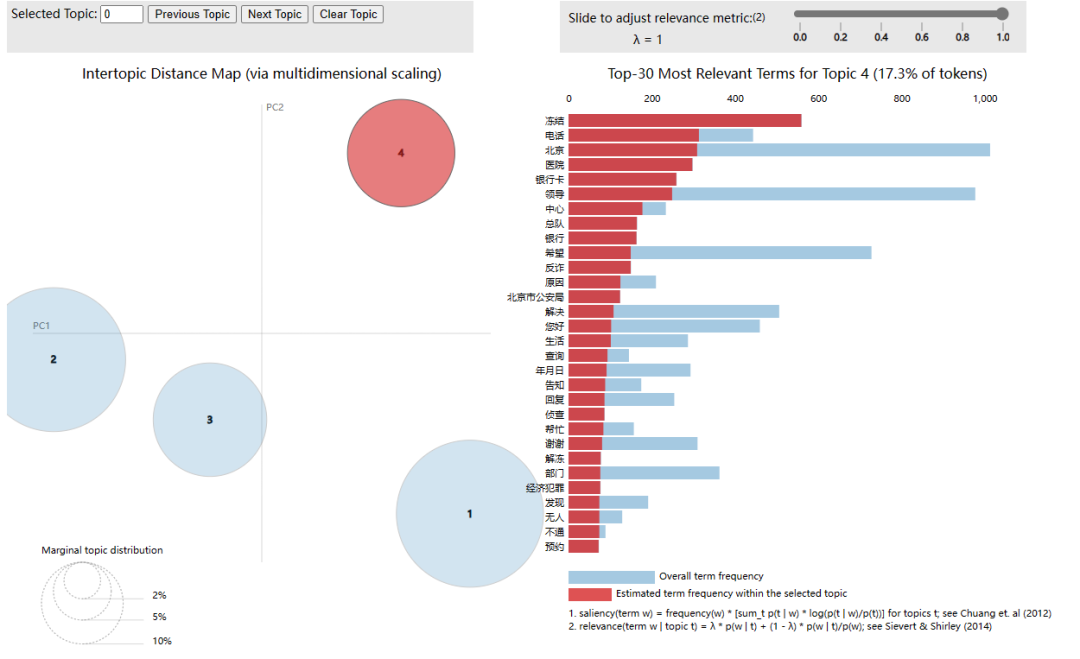
三、获取方式
案例数据代码获取方式
1、转发推送,保留1小时以上(不设分组),集赞30个
2、添加客服微信,发送朋友圈截图,并备注”领导留言板“,可免费获取资源
3、也可购买实证会员免费获取数据及30多门数据分析课程
点击查看往期汇编
一、案例库-:
二、案例库-Stata:
》
三、科研数据:
四、学习资料:
限时特惠:本站持续每日更新海量各大内部创业课程,一年会员仅需要98元,全站资源免费下载
点击查看详情
站长微信:Jiucxh
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。