()函数是PHP中的一个字符串截取函数,它可以截取一个多字节字符串中的一部分,并返回截取后的新字符串。与普通的()函数不同,()可以正确地处理多字节字符(如中文、日文等)substr,确保截取后的字符串不会出现乱码或截取不准确的情况。这对于处理国际化的项目中文本的读写操作非常有用。
()函数格式如下:
string mb_substr ( string $str , int $start [, int $length [, string $encoding ]] )
其中,$str表示要截取的字符串,$start表示截取开始的位置(从0开始计),$表示要截取的长度,$表示字符串编码方式,默认为当前脚本的字符编码方式(通常为UTF-8)。
使用示例:示例1:
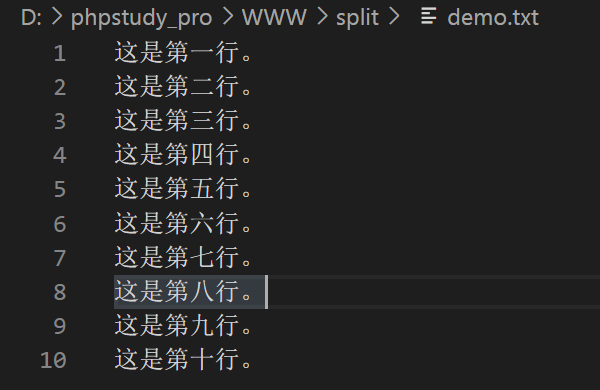
$str = "今天是个好日子";
echo mb_substr($str, 0, 2); // 输出“今天”
由于中文字符占2个字节,因此截取前2个字符即可得到“今天”。
示例2:
$str = "abcdefg你好";
echo mb_substr($str, 1, 4); // 输出"bcde"
由于中文字符占2个字节,因此截取从第1个字符开始的4个字符即可得到“bcdef”。
示例3:
$str = "abcdefg你好";
echo mb_substr($str, 4); // 输出“g你好”
如果省略了第3个参数(即截取的长度),则会一直截取直到字符串末尾。
需要注意的是,当指定的$start位置超出了字符串的长度时,()函数将返回一个空字符串。另外,当$参数为负数时,函数将会忽略它,截取到字符串末尾。
在实现多语言网站时,会用到类似的截取字符串工具。在这种情况下substr,使用()函数比较方便,可以保证正确处理多字节字符,不影响页面的显示效果。
()函数是一种非常实用的PHP字符串截取函数,能够正确处理多字节编码中文、日文等字符,使用起来非常方便。对于许多需要处理多语言网站或国际化项目的开发者来说,熟练掌握()函数是非常必要的。
限时特惠:本站持续每日更新海量各大内部创业课程,一年会员仅需要98元,全站资源免费下载
点击查看详情
站长微信:Jiucxh
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。