公开资料显示,北京面壁智能科技有限责任公司成立于2022年8月,核心产品包括全流程大模型高效加速平台和CPM大模型。今年4月,面壁智能完成新一轮数亿元融资,由华为哈勃领投分词器,春华创投、北京市人工智能产业投资基金等跟投,知乎作为战略股东持续跟投支持。
在该团队道歉前,面壁智能的联合创始人兼CEO李大海已在朋友圈发文回应,披露了-V能够与一样识别出“清华简”战国古文字的新证据,而由团队扫描并人工批注的该古文字数据并未对外公开,证实了-V模型涉嫌抄袭。
李大海表示,团队对这件事深表遗憾:“我们希望团队的好工作被更多人关注与认可分词器,但不是以这种方式……一方面感慨这也是一种受到国际团队认可的方式,另一方面呼吁大家共建开放、合作、有信任的社区环境。”
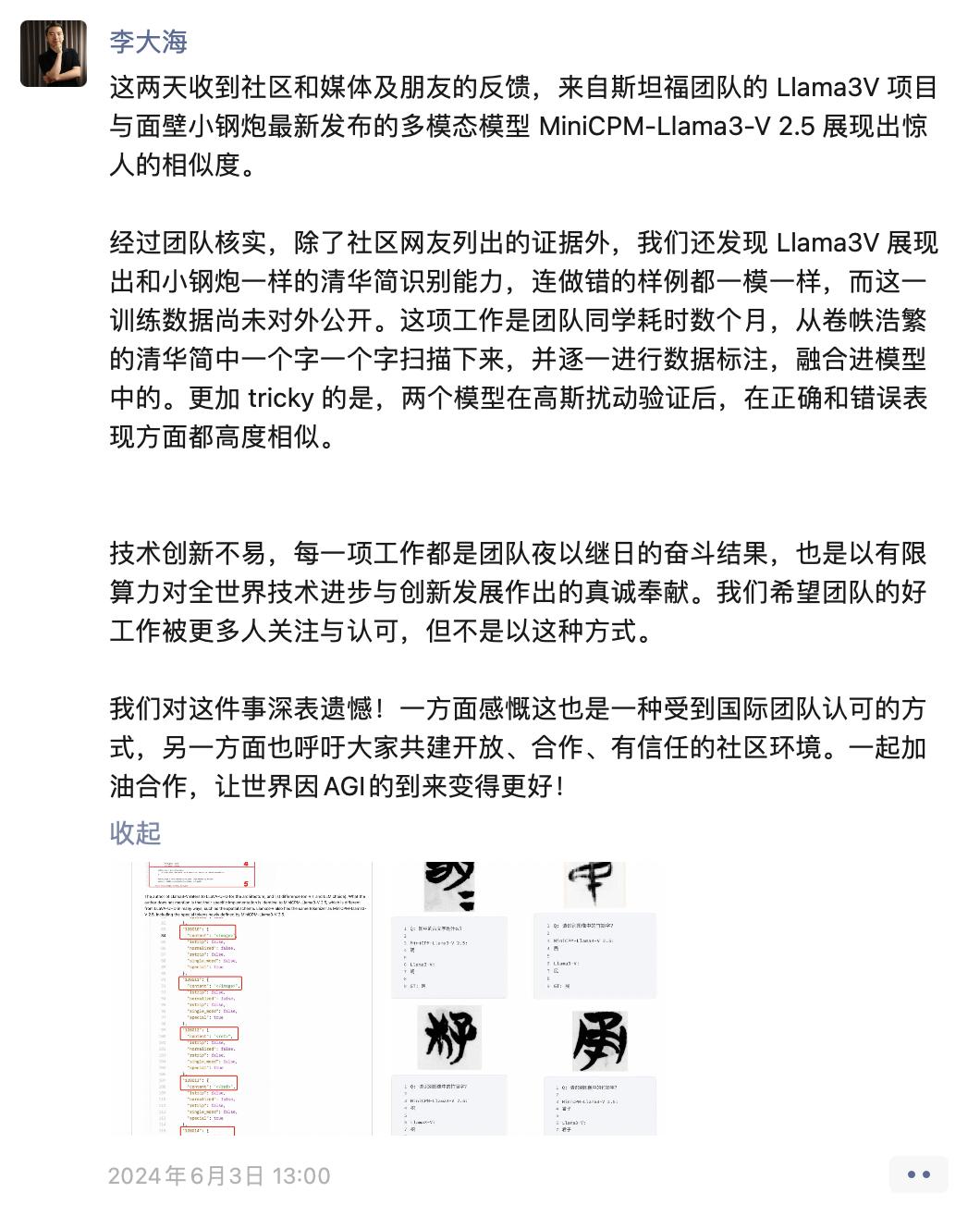
面壁智能CEO李大海的朋友圈回应
这场风波起源于5月29日。当日,斯坦福大学的一个研究团队在开源社区中发布了名为“-V”的模型,称只要500美元(约合人民币3622元)就能训练出一个SOTA多模态模型,且效果比肩知名大模型GPT-4V、 Ultra与 Opus。
由于该团队的三位作者都来自斯坦福大学,又拥有在特斯拉、和亚马逊等科技大厂的相关经历,发布该模型的X文章很快获得超过30万的浏览量,该模型也迅速在 Face首页的模型热度名单上冲进前排。
然而,不久后,开源社区内开始出现怀疑声,质疑-V是在“套壳”面壁智能于今年5月中旬刚刚发布的最新8B多模态小模型--V 2.5,且没有在项目中提到任何关于后者的信息。
对此,-V团队回应称其“只是使用了--V 2.5的(分词器)”,并称团队在--V 2.5发布前就已经开始了这项工作。
6月2日,网友在-V的页面上对此事进行了还原,并列举出大量的代码证据。该网友称自己在-V的发布页面下提出了疑问,但-V团队迅速删帖并对-V模型进行隐藏处理,所以来提醒-V团队关注此事。
质疑-V项目的帖子。来源:
证据显示,-V项目使用了与--V 2.5项目基本完全相同的模型结构和代码实现。另外, Face 发布页面上的历史记录显示,-V的作者曾在该页面上直接导入了-V的代码,然后改名为-V。
在该帖的回复中,网友们纷纷建议向斯坦福大学举报此事。有评论指出,虽然套用开源模型且没有致谢的做法可能只是造成了一些侵权,但由于-V的团队在网络上对该模型进行了大力宣传,或将在开源领域造成广泛的负面影响。
值得一提的是,在-V团队道歉前,斯坦福人工智能实验室主任克里斯托弗·大卫·曼宁( David )也在X平台上发文谴责这一抄袭行为,并称“是很好的开源作品”。
对于此事,面壁智能首席科学家、清华大学长聘副教授刘知远也在知乎上发表了回应,称这次事件让他感慨“过去十几年科研经历的斗转星移”:“从横向来看,我们显然仍与国际顶尖工作如Sora和GPT-4o有显著差距;同时,从纵向来看,我们已经从十几年的,快速成长为人工智能科技创新的关键推动者。面向即将到来的AGI时代,我们应该更加自信积极地投身其中。”
限时特惠:本站持续每日更新海量各大内部创业课程,一年会员仅需要98元,全站资源免费下载
点击查看详情
站长微信:Jiucxh