
HBase 优化JVM调优内存调优
一般安装好的HBase集群,默认配置是给和 1G的内存,而默认占0.4,也就是400MB。显然给的1G真的太少了。
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -Xms2g -Xmx2g"
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -Xms8g -Xmx8g"这里只是举例,并不是所有的集群都是这么配置。
==要牢记至少留10%的内存给操作系统来进行必要的操作==
如何给出一个合理的JVM 内存大小设置,举一个官方提供的例子吧。
比如你现在有一台16GB的机器,上面有服务、 和(这三位一般都是装在一起的),那么建议按 照如下配置设置内存:
如果同时运行的话,将是除了以外使用内存最大的服务。如果没有的话,可以调整到大概一半的服务器内存。
Full GC调优
由于数据都是在里面的,只是做一些管理操作,所以一般内存问题都出在上。
JVM提供了4种GC回收器:
一般会采取两种组合方案
和CMS的组合方案 PTS="$PTS -Xms8g -Xmx8g -XX:+ -XX:+"G1GC方案 PTS="$PTS -Xms8g -Xmx8g -XX:+ -XX:=100"
怎么选择呢?
一般内存很大(32~64G)的时候,才会去考虑用G1GC方案。
如果你的内存小于4G,乖乖选择第一种方案吧。
如果你的内存(4~32G)之间,你需要自行测试下两种方案,孰强孰弱靠实践。测试的时候记得加上命令
-XX:+ -XX:+ -XX:+icy
MSLAB和In (.X才有)
HBase自己实现了一套以为最小单元的内存管理机制,称为 MSLAB(-Local )
跟MSLAB相关的参数是:
在.0版本中,为了实现更高的写入吞吐和更低的延迟,社区团队对做了更细粒度的设计。这里,主要指的就是In 。
开启的条件也很简单。
..type=BASIC # 可选择NONE/BASIC/EAGER
具体这里不介绍了。
自动拆分
的拆分分为自动拆分和手动拆分。自动拆分可以采用不同的策略。
拆分策略
0.94版本的策略方案
hbase..max.
通过该参数设定单个的大小,超过这个阈值就会拆分为两个。
(默认)
文件尺寸限制是动态的,依赖以下公式来计算
Math.min(^3 * , Size)
假如
hbase...flush.size定义为128MB,那么文件 尺寸的上限增长将是这样:
刚开始只有一个文件的时候,上限是256MB,因为1^3 1282 = 256MB。当有2个文件的时候,上限是2GB,因为2^3 128 2 。当有3个文件的时候,上限是6.75GB,因为3^3 128 2 = 。以此类推,直到计算出来的上限达到 hbase..max.所定义的10GB。
除了简单粗暴地根据大小来拆分,我们还可以自己定义拆分点。
是
的子类,在前者的基础上增加了对拆分点(,拆分点就是被拆分处的)的定义。它保证了有相同前缀的不会被拆分到两个不同的里面。这个策略用到的参数是
. :前缀长度
那么它与
区别,用两张图来看。
默认策略为

策略

如果你的前缀划分的比较细,你的查询就比较容易发生跨查询的情况,此时采用
较好。
所以这个策略适用的场景是:
该策略也是继承自
,它也是根据你的前缀来进行切分的。唯一的不同就是:
是根据的固定前几位字符来进行判断,而
是根据分隔符来判断的。在有些系统中的前缀可能不一定都是定长的。
使用这个策略需要在表定义中加入以下属性:
.:前缀分隔符
比如你定义了前缀分隔符为_hbase,那么和的前缀就分别是host1和。
y
如果你的系统常常会出现热点,而你对性能有很高的追求, 那么这种策略可能会比较适合你。它会通过拆分热点来缓解热点 的压力,但是根据热点来拆分也会带来很多不确定性因 素,因为你也不知道下一个被拆分的是哪个。
olicy
这种策略就是永不自动拆分。
如果你事先就知道这个Table应该按 怎样的策略来拆分的话,你也可以事先定义拆分点 ()。所谓拆分点就是拆分处的,比如你可以按26个 字母来定义25个拆分点,这样数据一到HBase就会被分配到各自所属的 里面。这时候我们就可以把自动拆分关掉,只用手动拆分。
手动拆分有两种情况:预拆分(pre-)和强制拆分 ( )。
推荐方案
一开始可以先定义拆分点,但是当数据开始工作起来后会出现热点 不均的情况,所以推荐的方法是:
用预拆分导入初始数据。然后用自动拆分来让HBase来自动管理。
==建议:不要关闭自动拆分。==
的拆分对性能的影响还是很大的,默认的策略已经适用于大 多数情况。如果要调整,尽量不要调整到特别不适合你的策略
优化
一个只有一个。
的工作原理:读请求到HBase之后先尝试查询,如果获取不到就去HFile()和中去获取。如果获取到了则在返回数据的同时把Block块缓存到中。它默认是开启的。
如果你想让某个列簇不使用,可以通过以下命令关闭它。
alter '', =>{NAME => 'cf',=>'false'}
的实现方案有
LRU
在0.92版本 之前只有这种的实现方案。LRU就是Least Used, 即近期最少使用算法的缩写。读出来的block会被放到中待 下次查询使用。当缓存满了的时候,会根据LRU的算法来淘汰block。被分为三个区域,
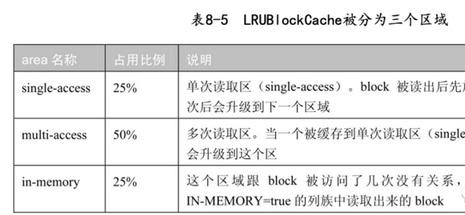
看起来是不是很像JVM的新生代、年老代、永久代?没错,这个方案就是模拟JVM的代设计而做的。
Slab Cache
实际测试起来对Full GC的改善很小,所以这个方案最后被废弃了。不过它被废弃还有一个更大的原因,这就是有另一个更好的Cache方案产生了,也用到了堆外内存,它就是。
Cache
Cache默认也是开启的,如果要关闭的话
alter '', =>{ => 'true'}
它的配置项:
在的时代,,是跟一起使用的,每一 个Block被加载出来都是缓存两份,一份在一份在, 这种模式称之为。读取的时候作为L1层缓存 (一级缓存),把作为L2层缓存(二级缓存)。
在的时代,也不是单纯地使用,但是这回 不是一二级缓存的结合;而是另一种模式,叫组合模式 ()。具体地说就是把不同类型的Block分别放到 和中。
Index Block和Bloom Block会被放到中。Data Block被直 接放到中,所以数据会去查询一下,然后再去 中查询真正的数据。其实这种实现是一种更合理的二级缓 存,数据从一级缓存到二级缓存最后到硬盘,数据是从小到大,存储介质也是由快到慢。考虑到成本和性能的组合,比较合理的介质是:使用内存->使用SSD->HFile使用机械硬盘。
总结
关于和单独使用谁比较强,曾经有人做 过一个测试。
从整体上说的性能好于,但由于Full GC的存在,在某些时刻JVM会停止响应,造成服务不可用。所以适当的搭配 可以缓解这个问题。
HFile合并
合并分为两种操作:
合并策略
从旧到新地扫描HFile文件,当扫描到某个文件,该文件满足以下条件:
该文件大小 < 比它更新的所有文件的大小总和 *
.ratio(默认1.2)
实际情况下的
算法效果很差,经常引 发大面积的合并,而合并就不能写入数据,经常因为合并而影响IO。所 以HBase在0.96版本之后修改了合并算法。
olicy
0.96版本之后提出了olicy算法,并且把该 算法作为了默认算法。
算法变更为
该文件大小 < (所有文件大小总和 - 该文件大小) *
.ratio(默认1.2)
如果该文件大小小于最小合并大小(),则连上面那个公式都不需要套用,直接进入待合并列表。最小合并大小的配置项:
.min.size。如果没设定该配置项,则使用
hbase...flush.size。
被挑选的文件必须能通过以上提到的筛选条件,并且组合内含有的文件数必须大于
.minhbase,小于
.max。
文件太少了没必要合并,还浪费资源;文件太多了太消耗资源,怕 机器受不了。
挑选完组合后,比较哪个文件组合包含的文件更多,就合并哪个组 合。如果出现平局,就挑选那个文件尺寸总和更小的组合。
这个合并算法其实是最简单的合并算法。严格地说它都不算是一种合并算法,是一种删除策略。
策略在合并时会跳过含有未过期数据的 HFile,直接删除所有单元格都过期的块。最终的效果是:
这个策略不能用于什么情况
表没有设置TTL,或者TTL=。表设置了,并且 >
解决的是一个基本的问题:最新的数据最 有可能被读到。
配置项
配置项好像很复杂的样子,举个例子画个图就清楚了。
假设基本窗口宽度 (
.date..base..) = 1。最小合并数量(
.min) = 3。层次增长倍数 (
.date...per.tier) = 2。
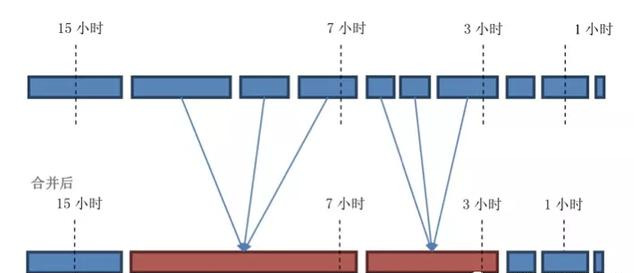
这个策略非常适用于什么场景
这个策略比较适用于什么场景
这个策略不适用于什么场景
cy
该策略在读取方面稳定。
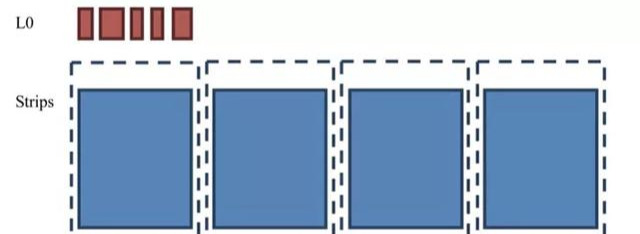
那么什么场景适合用cy
总结
请详细地看各种策略的适合场景,并根据场景选择策略。
限时特惠:本站持续每日更新海量各大内部创业课程,一年会员仅需要98元,全站资源免费下载
点击查看详情
站长微信:Jiucxh


