分布式 的兴起
背景
在大模型领域,随着模型参数规模的扩大和上下文长度增加,算力消耗显著增长。在 LLM 推理过程中火山互联,如何减少算力消耗并提升推理吞吐已经成为关键性优化方向。以多轮对话场景为例火山互联,随着对话轮数增加,历史 token 重算占比持续增长。实验数据表明(如图1),当每轮输入为 8k 时,运行 6 轮后,历史 token 重复计算占比超过 80%,直接导致了 GPU 算力的冗余消耗。在此背景下,构建高效的历史 token 计算结果缓存机制,理论上可以实现对重复计算过程的智能规避,从而显著提升计算资源的利用效率。
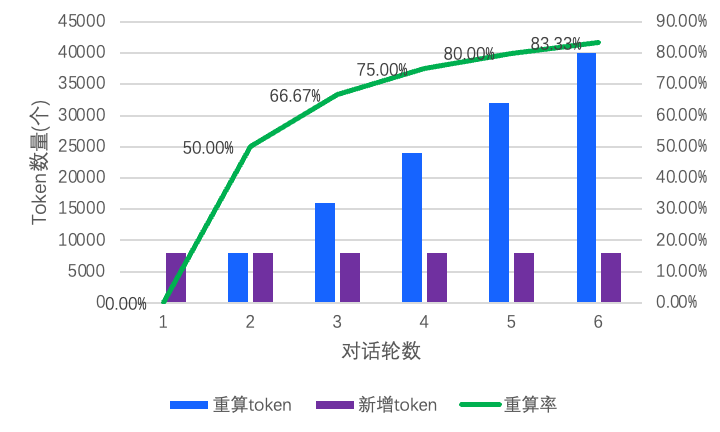
图1 对话轮数及重算率的变化
在应对上述技术挑战中,技术应运而生。
作为现代推理框架的核心组件, 能显著优化系统性能。 以 vLLM 为例,其通过 Cache 和 技术,构建了基于本地 HBM 的 Local 方案。该方案中,缓存重用率(Cache 可被重复使用的比例)作为核心指标,通常认为与缓存容量呈正相关关系,即空间越大重用率越高,然而 Local 受限于本地存储空间,容易遇到瓶颈。
从实验数据看出(如图2),在 H20 硬件平台运行 LLaMA-70B 模型时,每处理 1K token 需要 1.6GB 空间,导致 在 20 分钟内即突破内存阈值。这一内存墙问题会引发 频繁驱逐旧数据,导致重用率下降,进而严重影响 记忆长度,最终导致大量 token 重计算。为验证内存墙问题的影响,我们在 LLaMA-70B 模型的长文本场景测试中发现(如图 3),随着文档规模的增长,系统会快速触及单机内存上限,导致 token 吞吐量骤降 70%,迫使系统陷入算力重复消耗的恶性循环。

图2 内存占用
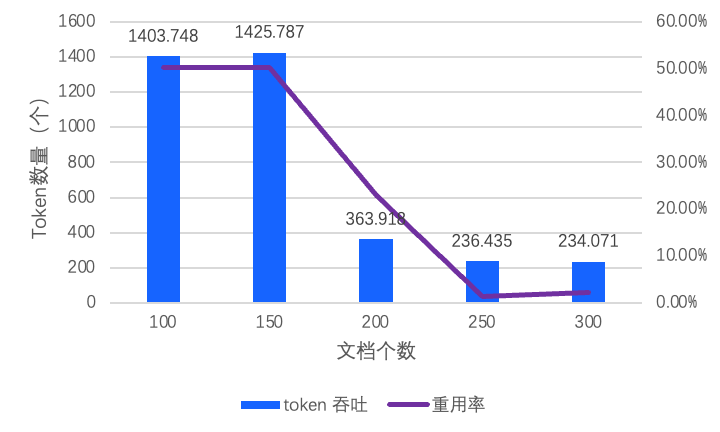
图3 Token 吞吐和 重用率
Local 另一个关键局限于在于无法多机共享,主要影响以下典型场景:

图4 不能共享的场景
需求
基于上述分析,我们构建了一个弹性高性能的分布式 服务,来优化 Local 方案的内存墙和不能共享的问题。区别于传统分布式服务,分布式 要求更高,对存储的核心挑战与需求如下:
火山引擎推理 解决方案
弹性极速缓存 EIC
弹性极速缓存 EIC( Cache)是火山引擎存储团队面向大语言模型推理场景推出的高性能分布式 缓存服务。随着互联网技术的演进与流量规模的激增,缓存技术逐渐成为系统架构的核心组件,火山引擎存储团队基于自身业务内部加速需求自主研发了 EIC,历经 4 年技术沉淀,该系统已支撑了公司内部存储、推理、广告推荐等大规模业务场景。
EIC 支持将内存和 SSD 组成一个分布式服务,构建多层缓存体系,实现显存容量的灵活扩展与计算资源的高效解耦。还支持和 GPU 混合部署,将 GPU 剩余显存、内存和磁盘统一池化管理,在提升计算效率的同时显著扩展上下文长度,成为加速推理框架的核心链路。基于通用模型和推理引擎,无缝兼容主流大语言模型架构,达成单客户端百 GB 级 吞吐与亚毫秒级响应,满足高并发、低延迟的生成式 AI 场景需求。
EIC 核心特性
缓存池化:多级缓存、数据流动
EIC 通过整合 GPU 集群闲置内存和磁盘,构建分布式缓存池,突破单机内存墙限制。分布式内存池化的核心目标是基于统一的多级存储资源池化管理(GPU 显存、CPU 内存、SSD及其他缓存系统),实现显存容量的灵活扩展与计算资源的高效解耦。

图5 多级透明缓存
推理缓存 至分布式缓存后,具备以下优势:
低时延:GPU RDMA
GDR 可以实现全链路内存零拷贝,支持极低的访问时延。在不同 IO 大小的测试中,GDR 的表现良好(图 7),时延可以达到 TCP 或 RDMA 的十分之一。

图6 GDR 工作示意图

图7 GDR 性能对比
EIC 与 Local 在实际推理场景中的效果对比如下:
结论:得益于 EIC 低时延和大容量带来的缓存高复用,同等算力条件下,推理吞吐性能可提升 3 倍以上;若维持原有性能指标,算力需求可大幅缩减,实现性能与成本的双重优化。

图8 EIC 推理框架以存代算性能对比
高吞吐:多网卡、拓扑亲和、模型高速加载
模型分发场景中,推理冷启动对模型加载的速度要求较高,模型加载的速度决定了推理服务的弹性能力。随着模型的增长,传统存储服务的加载速度逐渐缓慢。EIC 通过分布式缓存,实现模型文件到推理框架的高速加载,显著提升推理服务弹性。我们对比了模型在 H20 机型上从 NVMe SSD (传统存储服务的性能基线) 和 从 EIC 的加载速度,测试数据显示(图9):

图9 EIC 推理框架模型加载性能对比
为应对大模型高并发场景的 吞吐需求,EIC 通过多网卡并行传输和负载均衡技术,大幅提升了系统性能上限;同时为了解决不同 GPU 间访问网卡的时延差异,EIC 支持感知 GPU 和网卡拓扑结构,基于亲和性来选择最优网卡传输数据,达到时延和吞吐的极致优化(如图 10)。GPU 机型的 Root 是 级别,可转化为 NUMA 级别亲和,比如 Mem0 利用 R0 网卡和 R1 网卡发送延迟更低,GPU0 利用 R0 网卡发送延迟更低,我们测试多种配置场景,依赖多网卡、拓扑亲和等特性,单机可以轻松突破 100GB/s 带宽(图 11)。
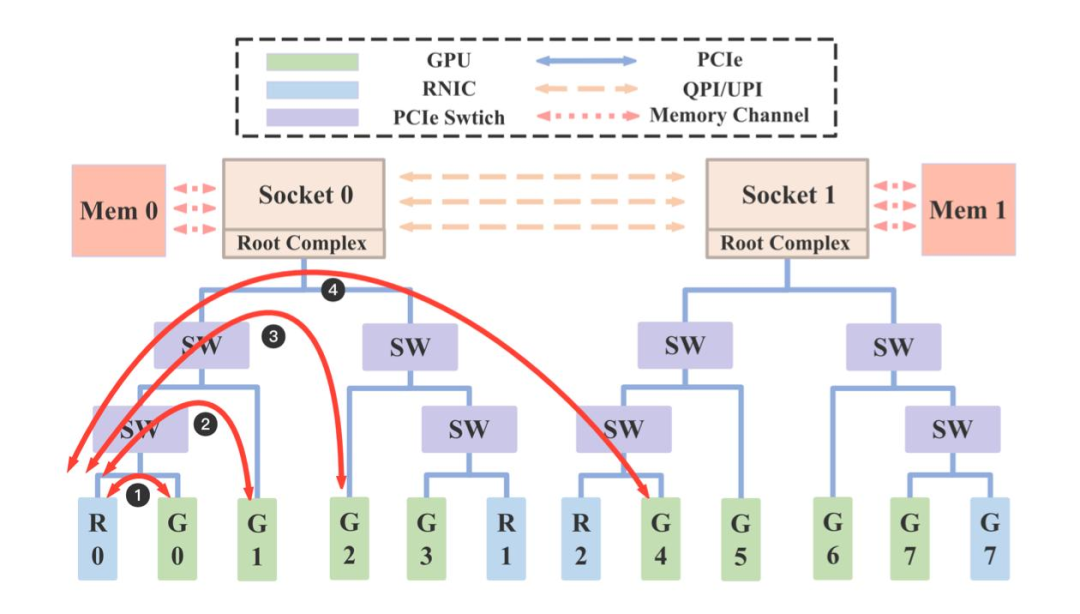
图10 GPU 网络亲和示意图

图11 EIC 读带宽性能测试
高易用: 切分
EIC 支持多 能力,可以实现数据分类,围绕 支持以下特性:
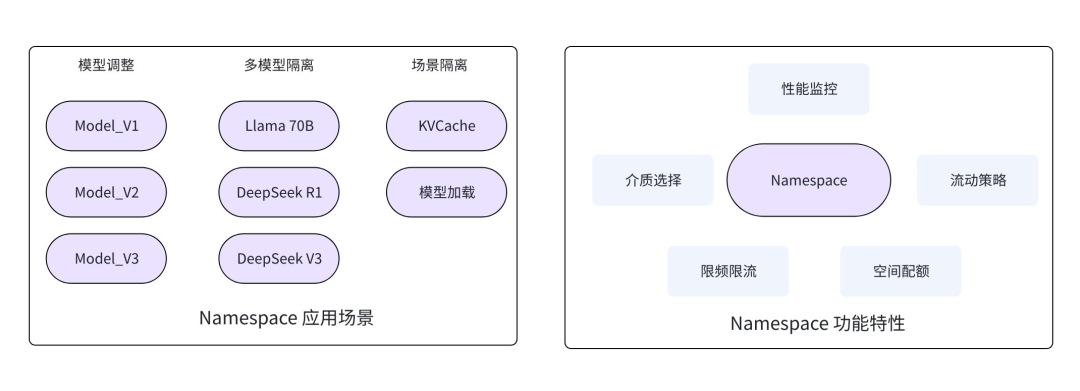
图12 特性及应用场景
在 LLM 场景中, 能力有以下应用,满足实际场景需求:
生态兼容:AI 云原生和开源生态集成
EIC 支持用户利用其 GPU 服务器的空闲内存和 SSD 资源,构建半托管或者全托管的高性能缓存池,目前, EIC 管控服务基于火山引擎托管,既能够依托火山引擎的 VKE 构建服务,也可基于开源的 K8S 构建服务。我们积极融入开源生态,已完成对 vLLM、 以及 等推理框架的适配,并将其集成至火山引擎 AI 相关重要业务中。
开源生态集成
我们基于 vLLM、 与 的开源实现,开发了 KV 缓存共享(Cache Reuse and )技术。该技术已成功在 PD 分离和模型并行架构下实现高效共享。与传统方案相比,在长文本场景中,推理吞吐提升 3 倍,首次 token 生成时间(TTFT)降低 67%。同时,我们优化了模型加载链路,支持模型通过多网卡从 EIC 进行高速直传,以 -R1(642GB)模型为例,其加载时间可缩减至 13 秒,显著提升模型部署效率。目前,我们已完成 EIC 集成的预制镜像制作,并计划将其贡献至开源社区,与社区开发者共同打造更高效、灵活的推理解决方案。
云原生开箱即用
在 EIC 集成方面,我们提供的预制镜像与白屏化集群管理平台深度协同,用户仅需在集群管理页面一键操作,即可将 VKE 和自建 K8S 推理集群集成 EIC 服务,并自动生成适配 、vLLM 和 的 Helm Chart 包。借助该工具,推理框架的部署流程得到大幅简化,真正实现一键式快速启动。我们编制了详尽的最佳实践文档,围绕 VKE(容器服务)/ Yaml 及 Helm 两种主流部署方式,完整展示从环境配置、参数优化到服务上线的全流程操作指南,帮助用户快速掌握高效部署方法,降低技术门槛,加速 EIC 与推理框架的深度融合应用。
展望
未来 EIC 将继续从以下维度持续演进,进一步提升产品能力和用户体验,敬请期待:

图13 推理框架与 EIC 生态演进
限时特惠:本站持续每日更新海量各大内部创业课程,一年会员仅需要98元,全站资源免费下载
点击查看详情
站长微信:Jiucxh