
前言
正则表达式一般用于字符串匹配,字符串查找和字符串替换。别小看它的作用,在工作学习中灵活运用正则表达式处理字符串能够大幅度提高效率,编程的快乐来得就是这么简单。
下面将由浅入深讲解正则表达式的使用。

简单入门 .
package test;
public class Test01 {
public static void main(String[] args) {
//字符串abc匹配正则表达式"...", 其中"."表示一个字符
//"..."表示三个字符
System.out.println("abc".matches("..."));
System.out.println("abcd".matches("..."));
}
}输出结果:
true
false类中有个( regex)方法, 返回值为布尔类型,用于告诉这个字符串是否匹配给定的正则表达式。
在本例中我们给出的正则表达式为...,其中每个.表示一个字符,整个正则表达式的意思是三个字符java 正则表达式,显然当匹配abc的时候结果为true,匹配abcd时结果为false。
Java中对正则表达式的支持
在java.util.regex包下有两个用于正则表达式的类, 一个是,另一个。
Java官方文档中给出对这两个类的典型用法,代码如下:
package test;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Test02 {
public static void main(String[] args) {
//[a-z]表示a~z之间的任何一个字符, {3}表示3个字符, 意思是匹配一个长度为3, 并且每个字符属于a~z的字符串
Pattern p = Pattern.compile("[a-z]{3}");
Matcher m1 = p.matcher("abc");
System.out.println(m2.matches());
}
}输出结果:true
可以理解为一个模式,字符串需要与某种模式进行匹配。 比如中, 我们定义的模式是一个长度为3的字符串, 其中每个字符必须是a~z中的一个。
我们看到创建对象时调用的是类中的方法,也就是说对我们传入的正则表达式编译后得到一个模式对象。 而这个经过编译后模式对象,,会使得正则表达式使用效率会大大提高,并且作为一个常量,它可以安全地供多个线程并发使用。
可以理解为模式匹配某个字符串后产生的结果。字符串和某个模式匹配后可能会产生很多个结果,这个会在后面的例子中讲解。
最后当我们调用m.()时就会返回完整字符串与模式匹配的结果。
上面的三行代码可以简化为一行代码:
System.out.println("abc".matches("[a-z]{3}"));但是如果一个正则表达式需要被重复匹配,这种写法效率较低。
匹配次数符号

代码示例:
package test;
public class Test03 {
private static void p(Object o){
System.out.println(o);
}
public static void main(String[] args) {
// "X*" 代表零个或多个X
p("aaaa".matches("a*"));
p("".matches("a*"));
// "X+" 代表一个或多个X
p("aaaa".matches("a+"));
// "X?" 代表零个或一个X
p("a".matches("a?"));
// \d A digit: [0-9], 表示数字, 但是在java中对"\"这个符号需要使用\进行转义, 所以出现\d
p("2345".matches("\d{2,5}"));
// \.用于匹配"."
p("192.168.0.123".matches("\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}"));
// [0-2]指必须是0~2中的一个数字
p("192".matches("[0-2][0-9][0-9]"));
}
}输出结果:全是true。
范围[]
[]用于描述一个字符的范围, 下面是一些例子:
package test;
public class Test04 {
private static void p(Object o){
System.out.println(o);
}
public static void main(String[] args) {
//[abc]指abc中的其中一个字母
p("a".matches("[abc]"));
//[^abc]指除了abc之外的字符
p("1".matches("[^abc]"));
//a~z或A~Z的字符, 以下三个均是或的写法
p("A".matches("[a-zA-Z]"));
p("A".matches("[a-z|A-Z]"));
p("A".matches("[a-z[A-Z]]"));
//[A-Z&&[REQ]]指A~Z中并且属于REQ其中之一的字符
p("R".matches("[A-Z&&[REQ]]"));
}
}输出结果:全是true。
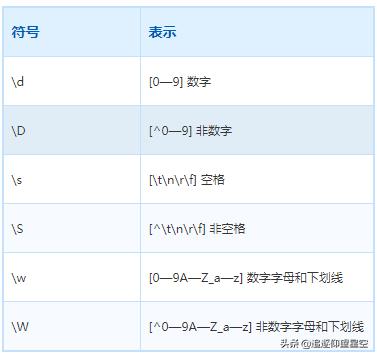
s w d S W D
关于
在Java中的字符串中,如果要用到特殊字符, 必须通过在前面加进行转义。
举个例子,考虑这个字符串"老师大声说:"同学们,快交作业!""。 如果我们没有转义字符,那么开头的双引号的结束应该在说:"这里,但是我们的字符串中需要用到双引号java 正则表达式, 所以需要用转义字符。
使用转义字符后的字符串为"老师大声说:"同学们,快交作业!"", 这样我们的原意才能被正确识别。
同理如果我们要在字符串中使用,也应该在前面加一个,所以在字符串中表示为"\"。
那么如何在正则表达式中表示要匹配呢? 答案为"\\"。
我们分开考虑:由于正则式中表示同样需要转义, 所以前面的\表示正则表达式中的转义字符,后面的\表示正则表达式中本身, 合起来在正则表达式中表示。
先来看代码示例:
package test;
public class Test05 {
private static void p(Object o){
System.out.println(o);
}
public static void main(String[] args) {
// s{4}表示4个空白符
p(" nrt".matches("\s{4}"));
// S表示非空白符
p("a".matches("\S"));
// w{3}表示数字字母和下划线
p("a_8".matches("\w{3}"));
p("abc888&^%".matches("[a-z]{1,3}\d+[%^&*]+"));
// 匹配
p("\".matches("\\"));
}
}
边界处理^
^在中括号内表示取反的意思[^], 如果不在中括号里则表示字符串的开头。
代码示例:
package test;
public class Test06 {
private static void p(Object o){
System.out.println(o);
}
public static void main(String[] args) {
/**
* ^ The beginning of a line 一个字符串的开始
* $ The end of a line 字符串的结束
* b A word boundary 一个单词的边界, 可以是空格, 换行符等
*/
p("hello sir".matches("^h.*"));
p("hello sir".matches(".*r#34;));
p("hello sir".matches("^h[a-z]{1,3}o\b.*"));
p("hellosir".matches("^h[a-z]{1,3}o\b.*"));
}
}输出结果:
true
true
true
false类
代码示例:
package test;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Test07 {
private static void p(Object o){
System.out.println(o);
}
public static void main(String[] args) {
Pattern pattern = Pattern.compile("\d{3,5}");
String s = "123-34345-234-00";
Matcher m = pattern.matcher(s);
//先演示matches(), 与整个字符串匹配.
p(m.matches());
//结果为false, 显然要匹配3~5个数字会在-处匹配失败
//然后演示find(), 先使用reset()方法把当前位置设置为字符串的开头
m.reset();
p(m.find());//true 匹配123成功
p(m.find());//true 匹配34345成功
p(m.find());//true 匹配234成功
p(m.find());//false 匹配00失败
//下面我们演示不在matches()使用reset(), 看看当前位置的变化
m.reset();//先重置
p(m.matches());//false 匹配整个字符串失败, 当前位置来到-
p(m.find());// true 匹配34345成功
p(m.find());// true 匹配234成功
p(m.find());// false 匹配00始边
p(m.find());// false 没有东西匹配, 失败
//演示lookingAt(), 从头开始找
p(m.lookingAt());//true 找到123, 成功
}
}如果一次匹配成功的话start()用于返回匹配开始的位置,
end()用于返回匹配结束字符的后面一个位置。
代码示例:
package test;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Test08 {
private static void p(Object o) {
System.out.println(o);
}
public static void main(String[] args) {
Pattern pattern = Pattern.compile("\d{3,5}");
String s = "123-34345-234-00";
Matcher m = pattern.matcher(s);
p(m.find());//true 匹配123成功
p("start: " + m.start() + " - end:" + m.end());
p(m.find());//true 匹配34345成功
p("start: " + m.start() + " - end:" + m.end());
p(m.find());//true 匹配234成功
p("start: " + m.start() + " - end:" + m.end());
p(m.find());//false 匹配00失败
try {
p("start: " + m.start() + " - end:" + m.end());
} catch (Exception e) {
System.out.println("报错了...");
}
p(m.lookingAt());
p("start: " + m.start() + " - end:" + m.end());
}
}输出结果:
true
start: 0 - end:3
true
start: 4 - end:9
true
start: 10 - end:13
false
报错了...
true
start: 0 - end:3替换字符串
类中的一个方法group(),它能返回匹配到的字符串。
代码示例:将字符串中的java转换为大写
package test;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Test09 {
private static void p(Object o){
System.out.println(o);
}
public static void main(String[] args) {
Pattern p = Pattern.compile("java");
Matcher m = p.matcher("java I love Java and you");
p(m.replaceAll("JAVA"));//replaceAll()方法会替换所有匹配到的字符串
}
}输出结果:
JAVA I love Java and you不区分大小写查找并替换字符串
我们要在创建模板模板时指定大小写不敏感。
public static void main(String[] args) {
Pattern p = Pattern.compile("java", Pattern.CASE_INSENSITIVE);//指定为大小写不敏感的
Matcher m = p.matcher("java I love Java and you");
p(m.replaceAll("JAVA"));
}输出结果:
JAVA I love JAVA and you不区分大小写, 替换查找到的指定字符串
这里演示把查找到第奇数个字符串转换为大写,第偶数个转换为小写。
这里会引入类中一个强大的方法( sb, ),它需要传入一个进行字符串拼接。
public static void main(String[] args) {
Pattern p = Pattern.compile("java", Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher("java Java JAVA JAva I love Java and you ?");
StringBuffer sb = new StringBuffer();
int index = 1;
while(m.find()){
m.appendReplacement(sb, (index++ & 1) == 0 ? "java" : "JAVA");
index++;
}
m.appendTail(sb);//把剩余的字符串加入
p(sb);
}输出结果:
JAVA JAVA JAVA JAVA I love JAVA and you ?分组
先看一个示例:
package test;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Test10 {
private static void p(Object o) {
System.out.println(o);
}
public static void main(String[] args) {
Pattern p = Pattern.compile("\d{3,5}[a-z]{2}");
String s = "005aa-856zx-1425kj-29";
Matcher m = p.matcher(s);
while (m.find()) {
p(m.group());
}
}
}输出结果:
005aa
856zx
1425kj其中正则表达式"\d{3,5}[a-z]{2}"表示3~5个数字跟上两个字母,然后打印出每个匹配到的字符串。
如果想要打印每个匹配串中的数字,如何操作呢?
分组机制可以帮助我们在正则表达式中进行分组。规定使用()进行分组,这里我们把字母和数字各分为一组"(\d{3,5})([a-z]{2})"
然后在调用m.group(int group)方法时传入组号即可。
注意:组号从0开始,0组代表整个正则表达式,从0之后,就是在正则表达式中从左到右每一个左括号对应一个组。在这个表达式中第1组是数字, 第2组是字母。
public static void main(String[] args) {
Pattern p = Pattern.compile("(\d{3,5})([a-z]{2})");//正则表达式为3~5个数字跟上两个字母
String s = "005aa-856zx-1425kj-29";
Matcher m = p.matcher(s);
while(m.find()){
p(m.group(1));
}
}输出结果:
005
856
1425整理总结
以上就是对于正则表达式的一个总结和使用说明,愿正则表达式给你带来更愉快的编程体验。
限时特惠:本站持续每日更新海量各大内部创业课程,一年会员仅需要98元,全站资源免费下载
点击查看详情
站长微信:Jiucxh



