
导读
工欲善其事,必先利其器。 作为一种跨平台的编程语言,具有解释性、变异性、交互性和面向对象的特点,可应用于独立的项目开发。今天,公众号“冰河技术”作者、腾讯云 TVP 冰河老师,将为我们带来基于 + 手把手教学如何实现单词统计。
目录
1 原理与运行机制
2搭建 单机环境
3安装 运行环境
4基于 + 统计单词数量
5 总结
在过去的十数年间, 和 一直是大数据处理方向的黄金组合,而在近年来,号称将要取代 的 Mojo 火了,唱衰 的言论也一直在持续。随着以 为代表的大模型技术的横空出世,更是让这个领域迎来了新的挑战与转机。+,这对黄金搭档在 2023 年的今天,还有值得学习的价值吗?今天我们通过一篇手把手实战的项目案例,诠释经典背后的技术魅力。
在当今的大数据环境下,数据无时无刻不在产生着HADOOP三大核心组件,每天处理的数据量已经远远超出了单台计算机所能存储和计算的数据量。如何对这些数据进行存储和处理成为了大数据领域中的两大难题,而 的出现则有效解决了这一难题,其提供的两大核心技术:HDFS 分布式文件系统和 并行计算成功地为大数据的存储和计算提供了可靠保障。
本文将简单介绍 的基础知识、原理与运行机制,并且会从零开始搭建 本地模式,并基于 + 实现单词统计功能。
01
原理与运行机制
众所周知, 作为一个开源分布式系统基础框架,主要包含两大核心组件:HDFS 分布式文件系统和 分布式并行计算框架,这两大核心组件是 进行大数据处理的基础和基石,此外, 的重要组件还包括: 和 YARN 框架。目前, 主要由 软件基金会进行开发和维护。
其实,我们在使用 的过程中,不需要了解分布式系统底层的细节,在开发 分布式程序的时候,只需要简单地编写 map() 函数和 () 函数即可完成 程序的开发,并且能够充分利用 集群的大规模存储和高并行计算来完成复杂的大数据处理业务。
同时, 分布式文件系统的高度容错性和高可扩展性等优点使得 可以部署在廉价的服务器集群上,它能够大大节约海量数据的存储成本。 的高度容错性,有效保证了系统计算结果的准确性,并从整体上解决了大数据的可靠性存储和处理。
实际上, 核心(或重要)组件主要包括: 、HDFS 分布式文件系统、 分布式计算框架、YARN 资源调度框架,接下来,我们来简单了解 HDFS、 和 YARN 的运行流程。
1.1HDFS 分布式文件系统
首先, 会将一个大文件切分成 N 个小文件数据块,分别存储到不同的 上,具体如图1所示。
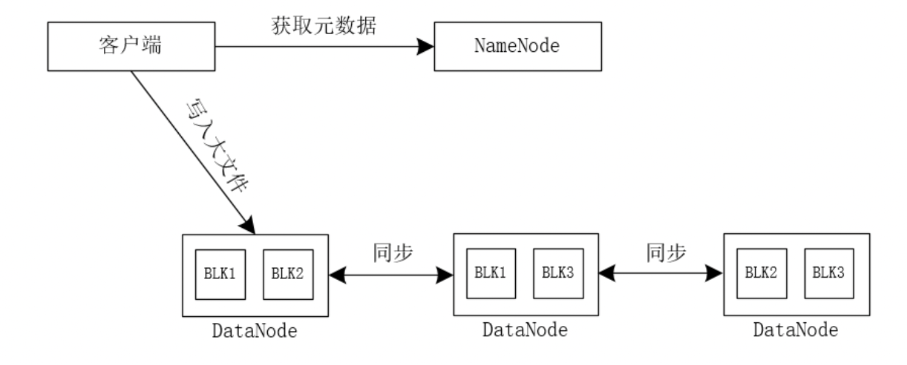
(图1)
当我们向 写入一个大文件时,客户端首先会向 服务器获取元数据信息,得到元数据信息后向相应的 写入文件, 框架会比较文件的大小与数据块的大小,如果文件的大小小于数据块的大小,则文件不再切分,直接保存到相应的数据块中;如果文件的大小大于数据块的大小, 框架则会将原来的大文件进行切分,形成若干数据块文件,并将这些数据块文件存储到相应的数据块中,同时,默认每个数据块保存3个副本存储到不同的 中。
由于 中 节点保存着整个数据集群的元数据信息,并负责整个集群的数据管理工作,所以,它在读/写数据上与其他传统分布式文件系统有些许不同之处。
读数据的简易流程如下图所示。
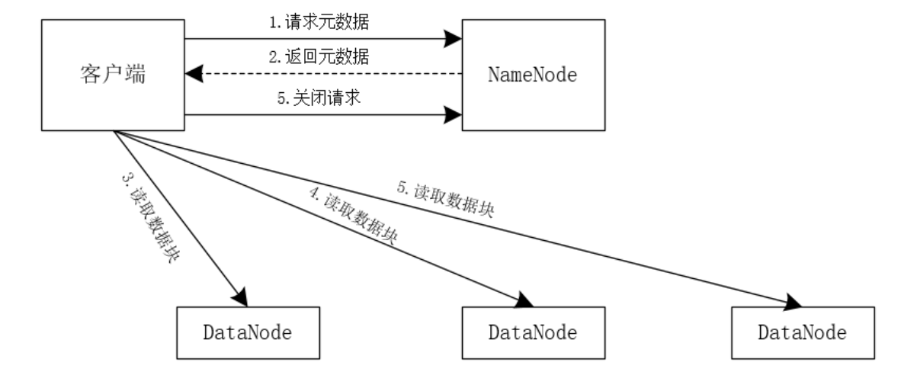
(图2)
写数据的简易流程如下图所示。
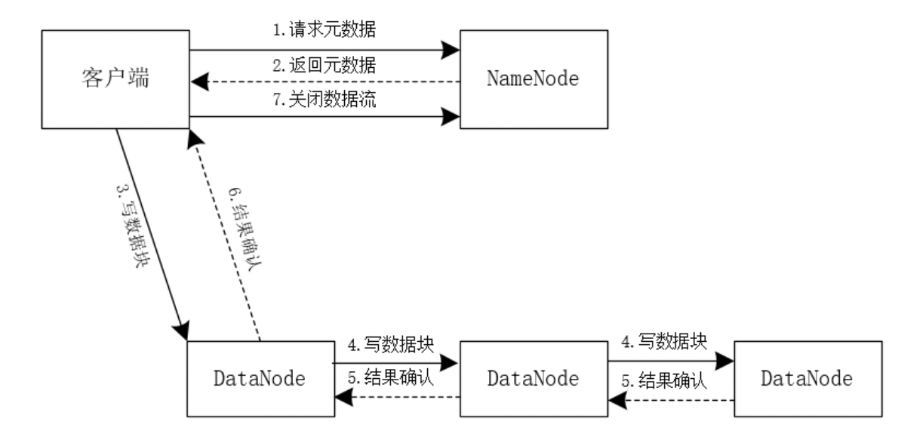
(图3)
1. 分布式计算框架
值得一提的是, 的 分布式计算框架会将一个大的、复杂的计算任务,分解为一个个小的简单的计算任务,这些分解后的计算任务会在 框架中并行执行,然后将计算的中间结果根据键进行排序、聚合等操作,最后输出最终的计算结果。
我们可以将这一整个 过程分为:数据输入阶段、map 阶段、中间结果处理阶段(包括 阶段和 阶段)、 阶段以及数据输出阶段。
数据输入阶段:将待处理的数据输入 系统。
map 阶段:map() 函数中的参数会以键值对的形式进行输入,经过 map() 函数的一系列并行处理后,将产生的中间结果输出到本地磁盘。
中间结果处理阶段:这个阶段又包含 阶段和 阶段,对 map() 函数输出的中间结果按照键进行排序和聚合等一系列操作,并将键相同的数据输入相同的 () 函数中进行处理(用户自身也可以根据实际情况指定数据的分发规则)。
阶段: 函数的输入参数是以键和对应的值的集合形式输入的,经过 函数的处理后,产生一系列键值对形式的最终结果数据输出到 HDFS 分布式文件系统中。
数据输出阶段:数据从 系统中输出到 HDFS 分布式文件系统。
上述简要执行过程如图4所示。
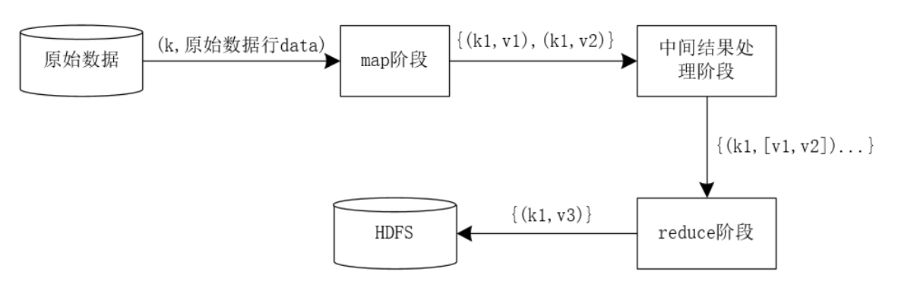
(图4)
原始数据以“(k, 原始数据行data)”的形式输入到 map 阶段,经过 map 阶段的 map() 函数一系列并行处理后,将中间结果数据以“{(k1, v1), (k1, v2)}”的形式输出到本地,然后经过 框架的中间结果处理阶段的处理,此中间结果处理阶段会根据键对数据进行排序和聚合处理,将键相同的数据发送到同一个 函数处理。
接下来我们就进入到 阶段, 阶段接收到的数据都是以“{k1,[v1, v2]…}”形式存在的数据,这些数据经过 阶段的处理之后,最终得出“{(k1,v3)}”样式的键值对结果数据,并将最终结果数据输出到 HDFS 分布式文件系统中。
1.3YARN 资源调度系统
YARN 框架主要负责 的资源分配和调度工作,其工作流程可以简化为图5所示。
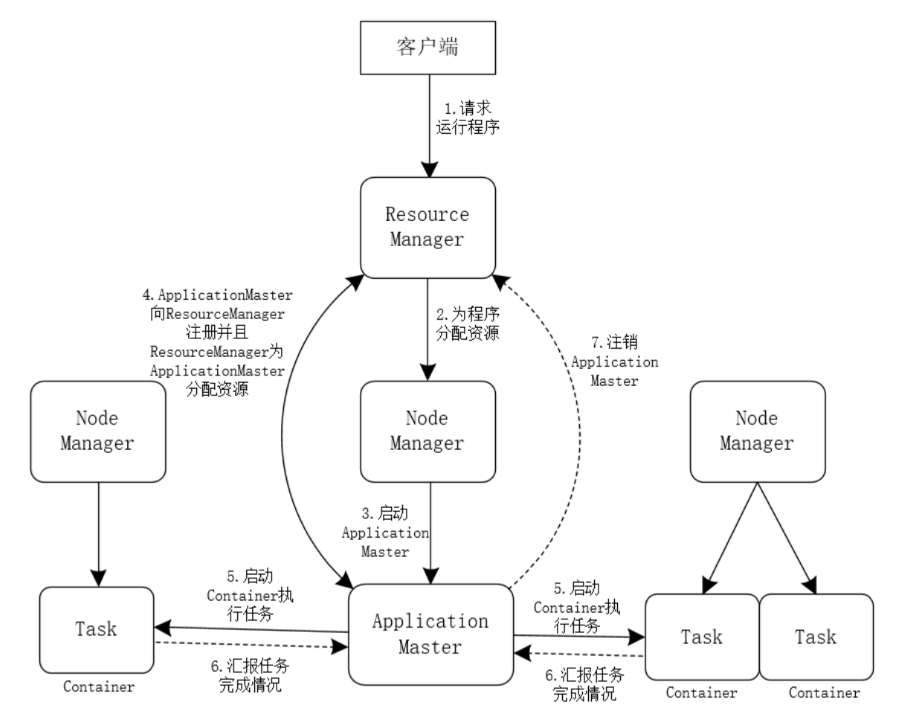
(图5)
02
搭建 单机环境
为了演示简单,这里我们搭建一套 单机环境为大家进行演示,并且默认大家已经安装好 操作系统并搭建好 JDK 环境。具体的环境信息如下所示。
注意:此部分操作是以 用户登录 服务器进行的。
2.1配置操作系统基础环境
我们主要是 用户来安装并启动 ,所以,我们需要先在服务器中添加 用户。
(1)添加 用户组和用户
首先,我们需要登录 root 账户,执行如下命令添加 用户组和用户。
groupadd hadoopuseradd -r -g hadoop hadoop
(2)赋予 用户目录权限
为了方便安装 环境,我们需要将服务器的 /usr/local 目录权限赋予 用户,具体命令如下所示。
mkdir -p /home/hadoopchown -R hadoop.hadoop /usr/local/chown -R hadoop.hadoop /tmp/chown -R hadoop.hadoop /home/
(3)赋予 用户 sudo 权限
在这里,我们主要通过 vim 编辑器编辑 /etc/ 文件来赋予 用户 sudo 权限,具体操作如下:
vim /etc/sudoers然后找到如下代码。
root ALL=(ALL) ALL接着,在此行代码后添加如下代码。
hadoop ALL=(ALL) ALL注意:由于“/etc/”是只读文件,所以保存并退出“/etc/”文件使用的是“wq!”。
(4)赋予 用户密码
我们采用如下方式赋予 用户密码。
[][]Changing password for user hadoop.New password: 输入密码BAD PASSWORD: The password is shorter than 8 charactersRetype new password: 再次输入密码passwd: all authentication tokens updated successfully.
(5)关闭防火墙
并在命令行输入如下命令,关闭 防火墙。
systemctl stop firewalldsystemctl disable firewalld
(6)配置 用户免密码登录
最后,以 用户登录服务器,分别输入如下命令来配置 用户免密码登录。
-t rsacat /home/hadoop/.ssh/id_rsa.pub >> /home/hadoop/.ssh/authorized_keyschmod 700 /home/hadoop/chmod 700 /home/hadoop/.sshchmod 644 /home/hadoop/.ssh/authorized_keyschmod 600 /home/hadoop/.ssh/id_rsassh-copy-id -i /home/hadoop/.ssh/id_rsa.pub 主机名(IP地址)
2.2搭建 本地模式
其实, 本地安装模式是三种安装模式中最简单的一种,我们只需要在 的 -env.sh 文件中配置 即可。
(1)下载 安装包
首先,我们需要在 命令行输入如下命令下载 安装包。
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz(2)解压 安装包
然后,在 命令行输入如下命令解压 安装包。
tar -zxvf hadoop-3.2.0.tar.gz (3)配置 环境变量
接着,在 /etc/ 文件中追加如下内容。
HADOOP_HOME=/usr/local/hadoop-3.2.0PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATHexport PATH HADOOP_HOME
然后输入如下命令使环境变量生效。
source /etc/profile(4)验证 的安装状态
在 命令行输入 命令验证 环境是否搭建成功,如下所示。
-bash-4.2$ hadoop versionHadoop 3.2.0Source code repository https://github.com/apache/hadoop.git -r e97acb3bd8f3befd27418996fa5d4b50bf2e17bfCompiled by sunilg on 2019-01-08T06:08ZCompiled with protoc 2.5.0From source with checksum d3f0795ed0d9dc378e2c785d3668f39This command was run using /usr/local/hadoop-3.2.0/share/hadoop/common/hadoop-common-3.2.0.jar
可以看到,我们输出了 的版本号,说明 环境搭建成功。
(5)配置
这里,我们主要通过配置 安装目录下的 /etc/ 目录下的 -env.sh 文件,例如我们将 安装在了 /usr/local/-3.2.0 目录下,所以,-env.sh 文件在 /usr/local/-3.2.0/etc/ 目录下。
首先,使用 vim 编辑器打开 -env.sh 文件,如下所示。
vim /usr/local/hadoop-3.2.0/etc/hadoop/hadoop-env.sh然后找到如下代码。
export JAVA_HOME=接着打开注释,我们将 JDK 的安装目录填写到等号后面。
export JAVA_HOME=/usr/local/jdk1.8.0_321至此, 搭建环境搭建完成。
03
安装 运行环境
操作系统中默认安装的 版本是2.7.5,这里,我们将 的版本升级为3.7.4。
注意:此部分操作是以 root 用户登录 服务器进行的。
3.1查看原有的 版本
我们直接在命令行输入 即可查看当前的 版本,如下所示。
[]Python 2.7.5 (default, Oct 14 2020, 14:45:30)[] on linux2Type "help", "copyright", "credits" or "license" for more information.
可以看到HADOOP三大核心组件, 默认安装的 版本为2.7.5。接下来,我们就将 的版本升级为3.7.4。
3.2安装 环境
(1)安装基础编译环境
首先,我们需要在服务器命令行输入如下命令安装基础编译环境。
yum install -y zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel zlib* libffi-devel readline-devel tk-devel(2)下载 安装包
然后,我们在服务器命令行输入如下命令下载 安装包。
wget https://www.python.org/ftp/python/3.7.4/Python-3.7.4.tgz(3)解压 安装包
接着,输入如下命令解压 安装包。
tar -zxvf Python-3.7.4.tgz(4)安装 环境
再进入 解压目录,如下所示。
cd Python-3.7.4随后我们依次输入如下命令安装 环境。
./configuremake && make install
(5)验证安装结果
最后,我们在命令行输入 命令即可验证安装结果,如下所示。
[]Python 3.7.4 (default, Nov 26 2023, 15:04:38)[] on linuxType "help", "copyright", "credits" or "license" for more information.
我们可以看到,输入 后成功输出了 的版本为3.7.4,说明我们 环境安装成功。
04
基于 + 统计单词数量
我们在实现统计单词数量的过程中,我们可以基于 分别实现 的 程序和 程序。
注意:此部分的操作是以 用户登录 服务器进行的。
4.1实现 程序
首先,我们在服务器的 /home// 目录下创建 .py 文件,具体代码如下所示。
import sys#读入标准输入中的数据for line in sys.stdin:#去除首尾空格line = line.strip()#以空格拆分每行数据words = line.split()#遍历单词列表,输出中间结果数据,以t分隔for word in words:print('%st%s' % (word, 1))
上述我们可以看到,.py 中的代码主要是从标准输入读取数据,并且去除读取数据的首尾空格,然后按照空格进行拆分后,遍历拆分后的数组,即可将数组的每个元素输出到标准输出。
4.2实现 程序
我们在服务器的 /home// 目录下创建 .py 文件,具体代码如下所示。
import sys#当前处理的单词handler_word = None#当前处理的数量handler_count = 0#当前中间结果中的单词word = None#从标准输入读取数据for line in sys.stdin:#移除首尾空格line = line.strip()#以t拆分map的中间结果数据word, count = line.split('t', 1)try:count = int(count)except ValueError:continueif handler_word == word:handler_count += countelse:if handler_word:#当前处理的统计结果到标准输出print('%st%s' % (handler_word, handler_count))handler_word = wordhandler_count = count#输出最后一个处理的单词统计信息if handler_word == word:print('%st%s' % (handler_word, handler_count))
可以看到,.py 的功能是读取 .py 输出的结果数据,并且会统计每个单词的数量,然后输出最终的结果数据。
4.3构建输入数据
我们在服务器的 /home//input 目录下新建 data.input 文件,文件内容如下所示。
hadoop mapreduce hive flumehbase spark storm flumesqoop hadoop hive kafkaspark hadoop storm
可以看到,我们在 data.input 文件中添加了一些单词数据作为测试数据文件。
4.4基于 运行 程序
基于 运行 程序,我们在命令行输入如下:
hadoop jar /usr/local/hadoop-3.2.0/share/hadoop/tools/lib/hadoop-streaming-3.2.0.jar -file /home/hadoop/python/mapper.py -mapper "python3 mapper.py" -file /home/hadoop/python/reducer.py -reducer "python3 reducer.py" -input /home/hadoop/input/data.input -output /home/hadoop/output
其中,上述命令的参数含义如下所示。
在输出的日志中存在如下信息,说明我们成功基于 运行了 编写的 程序。
INFO mapreduce.Job: map 100% reduce 100%INFO mapreduce.Job: Job job_local307776602_0001 completed successfull
接下来,我们查看 /home// 目录下的输出内容,如下所示。
-bash-4.2$ ll /home/hadoop/outputtotal 4-rw-r--r--. 1 hadoop hadoop 76 Nov 26 15:32 part-00000-rw-r--r--. 1 hadoop hadoop 0 Nov 26 15:32 _SUCCESS
接着,查看 part-00000 文件的内容,如下所示。
cat /home/hadoop/output/part-00000flume 2hadoop 3hbase 1hive 2kafka 1mapreduce 1spark 2sqoop 1storm 2
我们可以看到,在 part-00000 文件中输出了每个单词和对应的统计数量。
05
总结
最近一段时间以来,以 为代表的大模型非常火热,但这些大模型背后需要海量的数据作为人工智能学习和分析的依据。就其参数模型而言,也是动辄几千亿、上万亿的参数模型,其背后同样需要海量的数据作为分析的依据。尽管当今在线实时分析技术已经非常成熟,但是离线批处理技术作为数据分析的兜底措施与数据校对机制,在当今大数据和人工智能时代仍旧是不可或缺的重要技术组成部分。
不仅仅支持以 为核心的离线批处理技术,其提供的 HDFS 分布式文件系统更是支持海量数据的可靠存储。另外,尽管 内部的核心功能是使用 Java 编写的,但是 支持多种编程语言来实现海量数据的离线批处理技术,考虑到 在数据分析和统计方面的优势, 自然也支持基于 实现海量数据的离线批处理技术。所以,+ 仍旧是 时代,实现海量数据离线批处理分析和统计的重要组合技术。
*本文部分内容节选自《海量数据处理与大数据技术实战》

限时特惠:本站持续每日更新海量各大内部创业课程,一年会员仅需要98元,全站资源免费下载
点击查看详情
站长微信:Jiucxh

![quartz插件-[开源]热门技术构造、超轻量级 Kettle Web 大数据调度服务监控平台](http://www.jiuchuangxh.com/wp-content/themes/ripro-v2/assets/img/thumb.jpg)
