前言
最近在研究正则表达式,发现这个正则表达式在处理文本方面实在太牛了,下面分享一下。
概念
正则表达式( )就是用一个“字符串”来描述一个特征,然后去验证另一个“字符串”是否符合这个特征。比如表达式“ab+” 描述的特征是“一个 'a' 和 任意个'b' ”,那么 'ab', 'abb', '' 都符合这个特征。
作用
正则表达式可以用来:
(1)验证字符串是否符合指定特征,比如验证是否是合法的邮件地址。
(2)用来查找字符串,从一个长的文本中查找符合指定特征的字符串,比查找固定字符串更加灵活方便。
(3)用来替换,比普通的替换更强大。
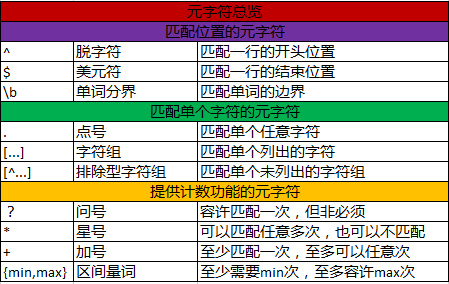
各种符号的意义
正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
元字符
描述
将下一个字符标记符、或一个向后引用、或一个八进制转义符。例如,“\n”匹配n。“n”匹配换行符。序列“\”匹配“”而“(”则匹配“(”。即相当于多种编程语言中都有的“转义字符”的概念。
匹配输入字行首。如果设置了对象的属性,^也匹配“n”或“r”之后的位置。
匹配输入行尾。如果设置了对象的属性,$也匹配“n”或“r”之前的位置。
匹配前面的子表达式任意次。例如,zo*能匹配“z”,也能匹配“zo”以及“zoo”。*等价于o{0,}
匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。
匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等价于{0,1}。
{n}
n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。
{n,}
n是一个非负整数。至少匹配n次。例如js 正则表达式,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。
{n,m}
m和n均为非负整数,其中n(?
此处用或任意一项都不能超过2位,如“(?
x|y
匹配x或y。例如,“z|food”能匹配“z”或“food”(此处请谨慎)。“[zf]ood”则匹配“zood”或“food”。
[xyz]
字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。
[^xyz]
负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”。
[a-z]
字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。
注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围; 如果出字符组的开头,则只能表示连字符本身.
[^a-z]
负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。
b
匹配一个单词边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的b就是匹配位置的)。例如,“erb”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。
B
匹配非单词边界。“erB”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。
cx
匹配由x指明的控制字符。例如,cM匹配一个-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。
d
匹配一个数字字符。等价于[0-9]。grep 要加上-P,perl正则支持
D
匹配一个非数字字符。等价于[^0-9]。grep要加上-P,perl正则支持
f
匹配一个换页符。等价于x0c和cL。
n
匹配一个换行符。等价于x0a和cJ。
r
匹配一个回车符。等价于x0d和cM。
s
匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ fnrtv]。
S
匹配任何可见字符。等价于[^ fnrtv]。
t
匹配一个制表符。等价于x09和cI。
v
匹配一个垂直制表符。等价于x0b和cK。
w
匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的"单词"字符使用字符集。
W
匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。
xn
匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,“x41”匹配“A”。“x041”则等价于“x04&1”。正则表达式中可以使用ASCII编码。
num
匹配num,其中num是一个正整数。对所获取的匹配的引用。例如,“(.)1”匹配两个连续的相同字符。
n
标识一个八进制转义值或一个向后引用。如果n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n为一个八进制转义值。
nm
标识一个八进制转义值或一个向后引用。如果nm之前至少有nm个获得子表达式,则nm为向后引用。如果nm之前至少有n个获取,则n为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则nm将匹配八进制转义值nm。
nml
如果n为八进制数字(0-7),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。
un
匹配n,其中n是一个用四个十六进制数字表示的字符。例如,u00A9匹配版权符号(©)。
p{P}
小写 p 是 的意思,表示 属性,用于 正表达式的前缀。中括号内的“P”表示 字符集七个字符属性之一:标点字符。
其他六个属性:
L:字母;
M:标记符号(一般不会单独出现);
Z:分隔符(比如空格、换行等);
S:符号(比如数学符号、货币符号等);
N:数字(比如阿拉伯数字、罗马数字等);
C:其他字符。
*注:此语法部分语言不支持,例:。
( )
将( 和 ) 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 1 到9 的符号来引用。
将两个匹配条件进行逻辑“或”(Or)运算。例如正则表达式(him|her) 匹配"it to him"和"it to her",但是不能匹配"it to them."。注意:这个元字符不是所有的软件都支持的。
自定义查找替换函数
今天我们研究一下替换的公式,看看正则表达式在处理文本上的威力:
首先,打开VBA编辑器:在任意模块下输入以下代码:建立一个查找替换的自定义函数()
代码如下:
(sStr As , , As ) As
Dim regEX As
Set regEX = (".")
regEX. = True
regEX. =
= regEX.(sStr, )
Set regEX =
End
下面我们就可以在工作表中使用这个函数了,前提是不要禁用宏,要把工作薄存成启用宏的工作薄。
实例
下面是运用公式的结果,是不是在处理不规则字符方面有重大突破呢?
注意在替换的字符串中$1代表正则表达式的第一个括号,$2代表正则表达式的第二个括号,运用这个功能可以颠倒字符串位置的顺序js 正则表达式,或在指定的字符后面添加需要的字符。
知识点
正则表达式规则比较复杂,可以从简单的做起,逐步深入,一点点吃透。
制造问题,制造困难,解决之
END
限时特惠:本站持续每日更新海量各大内部创业课程,一年会员仅需要98元,全站资源免费下载
点击查看详情
站长微信:Jiucxh