
这是菜鸟学的第45篇原创文章
阅读本文大概需要5分钟
都说正则表达式有点像密码,有的同学看到就头疼,感觉迷一样的。
那是因为你们没有掌握一些基本的要领,今天我们会讲9种常见的正则表达式的招式,(有同学会问这么多招,哪能记得住)
想要练成御剑飞行,基本功必须要扎实.这些都是最最基本的,哪怕死记硬背也要背住(其实2-3遍就能记住,真的不难)
插一句:
有一点要注意的字符串本身也用''转义,所以要特别注意,一般我们都建议使用的r前缀,就不用考虑转义的问题了
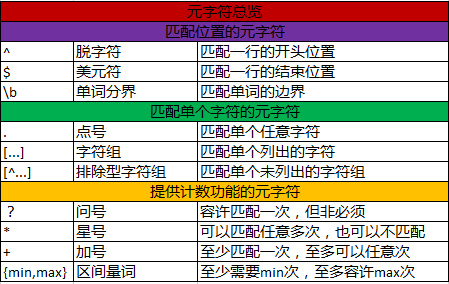
1.行的起始
先说一个简单的例子:匹配以cat开头的
patt=pile(r'^cat')
表示匹配以c作为一行的第一个字符,后面跟着a,后面跟着t
所以''就不会被匹配到,原因是因为cat在字符的里面
2.行的结尾
如何我们要是以某一个字符串结尾的,比如我们要查邮件是以
BR或者结尾的,如何匹配:我们用美元符号$来处理
import re
sentence='''Hi Jack:n
Python is a beautiful languagen
BR'''
patt=re.compile(r'(BR|Bestregards)$')
m=re.search(patt,sentence)
if m :
print 'match'
else:
print 'not match'
>>
match
$表示匹配的位置是从行的结束的,也就是锚定在行的末尾,然后从行的末尾往前匹配BR或者是,所以若你改成下面两种都匹配不到
='''Hi Jack:n
is a n
BRs'''
='''Hi Jack:n
is a n
'''
解释一下:
第一种情况,是把BR改成了BRs,所以匹配不到
第二种情况,是把改成了,所以也匹配不到
3.单词的边界
前面介绍了匹配行的开头和结尾,那么如何匹配单词的边界呢,简单正则里面有2个特殊字符b and B来匹配单词的边界 :
例如:
the #匹配包含有'the'的字符串
bthe #匹配任何以'the'开始的字符串
btheb #仅仅匹配单词'the'
Bthe #匹配任意包含'the'但不以'the'开头的单词
4.字符组
比如我们需要匹配'grey'或者'gray'的时候,怎么办,可以用正则的[]来表示,gr[ea]y,表示先找到g,然后找到r,然后找到e或者a,最后是一个y
import re
word='grey'
patt=re.compile(r'gr[ea]y')
m=re.match(patt,word)
if m :
print 'match'
else:
print 'not match'
>>
match
若把word改成'gray'也是匹配的
切记:字符组里面是匹配一个字符比如H[12345],表示H后面可以跟1或2或3或4或5,而不是12345,千万不要弄错了
5.多选结构
我们可以用'|'来匹配任意子表达式,'|'是一个非常简便的元字符,它的意思是"或",通过它我们能把不同的子表达式组合成一个总的表达式,比如'am'|'pm'就是能够同时匹配其中任意一个的正则表达式,回头再看上面的例子'gr[ea]y',其实能写成'grey|gray',或者'gr(e|a)y'
6.可选项元素
比如6月4号,这个6月可能写成'June'也可以写成'Jun',而且日期也有可能写作''或者'4th'或者4,我们可以写成(June|Jun)(|4th|4),但是有没有其他办法呢,可以用问号?表示可选项
我们分步来处理:
最后这个复杂的(June|Jun)(|4th|4)就可以变成了June?(|4(th)?),大家看懂了吗~~有点晕是把,没事吐吐就习惯了
7.重复出现
重复出现用+和*表示,但是二者有一些小的区别
其实说白了*比+多一种不出现的情况,匹配尽可能多的次数,如果实在匹配不到也不要紧,+也是匹配多次,但连一次匹配都无法完成,就报告失败
例如:
a* #匹配a,aa,aaa,...还有''
a+ #匹配a,aa,aaa,...
解释一下:
a*表示0个或者多个a,所以为0的时候,就是空字符
a+表示1个或者多个a,所以a至少要有1次
8.匹配重复的次数
1).比如我们想匹配前面的内容重复出现的次数,比如3次,或者是一个区间,比如1-3次,如何匹配:
import re
num_str='123aa45'
patt=re.compile(r'([1-9]{3})')
m=re.match(patt,num_str)
if m:
print m.group()
>>
123
表示出现1-9之间的任意一个数字,并且这个数字只能重复出现3次
2).为重复匹配次数设定一个区间
比如美国股票的代码,都是字符有大写的也有小写,基本都是在1到5个字母,如何用正则表达呢
简单[a-zA-Z]{1,5},就可以来匹配美国股票代码(1到5个字母)
9.排除型字符组
比如我们想匹配除了1到6以外的任何字符串,怎么办,简单用[^1-6],这个字符组中开头的^表示"排除的意思".(有同学会举手说,你刚才不是说^表示开头吗,怎么现在变成排除型了).
这位同学会抢答了,下面就是我要解释的,正则的复杂性:
比如:找出字母g后面的字母不是u
import re
words=['gold','Google','Sogu','Guess']
patt=re.compile(r'.*g[^u]')
for w in words:
m=re.match(patt,w)
if m:
print w
>>
gold
细心的同学会发现,我们的目的是要"找出字母g后面的字母不是u",为啥'Guess'不在输出结果里面,不是排除型吗,我先不说答案,大家先思考一下c 正则表达式,有兴趣的同学可以留言,我会解答.
好了中的正则表达式元字符就讲到这里啦,希望能给初学者一些启发,若有什么不懂的c 正则表达式,也可以留言跟我探讨交流.
"欢迎大家关注 菜鸟学",更多好玩有趣的原创教程,趣味算法,经验技巧,行业动态,尽在菜鸟学,一起来学吧

来源 | 菜鸟学
作者 |
限时特惠:本站持续每日更新海量各大内部创业课程,一年会员仅需要98元,全站资源免费下载
点击查看详情
站长微信:Jiucxh



